Abstract
This study is carried out within the framework of the Cyber Threat Intelligence (CTI) service hosted and developed by Intrinsec. This article introduce the first steps of our experimental research on using Artificial Intelligence to enhance the CTI workflow. The aim of the CTI platform is to monitor and collect public data feeds and to notify its subscriber on cyber related threat detection. One challenge of this platform is that it has to qualify the relevance and the criticality of a large amount of data. Several approaches inspired from machine learning and sentiment analysis were studied and will be the subject of forthcoming articles. Nonetheless, ahead of this work, the platform needs a way to extract natural language text in which it could perform a semantic analysis. This article will relate how we leveraged a syntactic analysis combined with deep learning models in order to perform a classification of the data according to text type with an accuracy of 93%. After presenting an overview of the data we worked with, it will describe the feature extraction process we came across, through tokenization and sequences computation. Finally, it will expose the results of a benchmark of several machine learning and deep learning models over the task of the text type classification.
The Cyber Threat Intelligence
The Cyber Threat Intelligence at Intrinsec is an intelligence on cyber threats service aimed at protecting its subscriber data assets regarding cyber related threats.
It relies on a team of analyst with various profiles (from economic intelligence to cybersecurity engineering) and on an on-premise data collection platform. The whole aim of the service is to provide a fully qualified cyber threat information feed to our customer. To do so, this platform collect data from hundreds of various sources through crawling and scanning techniques:
- Data sharing sites
- Social networks in a targeted way
- Online storages
- Documents indexed by search engines
- Data breaches
- Code sharing sites
After collecting and indexing those items, the platform will process customer assets (keywords) searches on the data. The matched items will give birth to notifications that will be manually qualified by analysts and finish their lives as alerts when relevance is ensured.
The issue
The whole process of the CTI has one major bottleneck, the « manual » qualification of many notifications by human analysts with lots of false positives. One promising way to address this bottleneck is to harness what Artificial Intelligence can offer. The objective is not to fully automatize the qualification process, a human interaction will always be required as even state of art deep learning models can barely infer prediction from totally unencountered data. As we are dealing with data from the whole of internet and we are looking for cyber threats, we cannot fully entrust such a critical task to a robot. Nevertheless, AI can provide helpers to prequalify alerts and thus guide analysts in various ways. The current literature is overflowing of papers and studies about text classification, semantic analysis, natural language processing etc. Yet only few tackles the problem of text syntax detection. The CTI platform gather data from all kind of sources, hence of all kind syntactic structure: social media posts, web page, programing code, configuration files, listings of all kind, etc. On top of that, many sources may generate any syntactic kind of content (a code repository may contain documentation, a forum post may contain a list of leaked mail addresses …).
This article will describe our endeavor to implement our own syntactic type classifier in order to detect and extract notification that contains Natural language text (of any language) on which we could later perform more specific semantic analysis.
Data overview
A preliminary step was to examine the data generated by the platform. We used a sample of two thousands random notifications taken over a period of one month to conduct this exploration.
As said before, their source can be diverse: forums, social networks, software hosting platforms, web pages, etc.
We began by a hand-labelling of the notification of the corpus. This was a long process that needed a first choice: what label to use? The first option was to do a binary classification with only two labels: Natural Language (the notifications contains readable text) or Not Natural Language.
As we would still have to go through every notification to label them, using more than two labels would give us more information without adding much to the initial cost.
After a first analysis, we decided to label the notification into four syntactic types of text:
Natural Language (NTL)
Notifications containing a majority of readable text.
For example:
- « The weather is really nice today. »
- « <a id=my_id> The weather is really nice today. </a> »
Directory Listing (DIR)
Notifications containing a majority of directories and files paths.
For example:
- « c://home/directory/myfile.xls »
- « /etc/directory/myfile.pb »
IP and/or URL Listing (IP/URL)
Notifications containing a majority of IP addresses and/or url addresses.
For example:
- « *website1.com = 0.0.0.0 *website2.com = 0.0.0.0 *website3.com = 0.0.0.0 *website3.com = 0.0.0.0 «
- « a.website.com b.website.com c.website.com a.website.co.uk t.website.fr »
Other Types (OTH)
All the other notifications that does not fit the above categories (code, hash, emails, etc.)
For example:
- « for i in range(0, n) »
- « ~ msgstr « Švýcarsko » #~ msgid « Czech Republic » #~ msgstr « Česká republika » #~ msgid « North America » »
- « IDABNUTYNBgkseifusqhkiGwggSjAgEAAoIBAQC »
The data repartition is as followed :
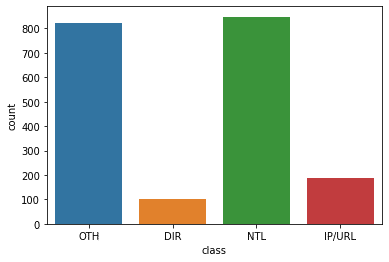
As you can see in the figure, the set is clearly unbalanced with the NTL and OTH classes in majority. This may cause a problem later with the model having false « good performances » by always predicting OTH and NTL.
Knowing the label to use for the notifications, we need a way to analyze them.
Tokenisation
The first step for nearly every job that involves working with textual data requires a way to tokenize the text.
According to Wikipedia, tokenization is:
> « the process of demarcating and possibly classifying sections of a string of input characters »
For example, a way to tokenize the sentence « it is a nice weather today » is to split by space, giving us the following list of tokens:

This may be enough for most use cases, but our problem requires more information about what separate word as they are essential to determine the syntax type of a text. In return, we do not need the word itself as we do not care about its meaning. Only an information about its composition should be useful.
For instance, take the case of a code sample: « print(f »Hello there {name} »)« , the tokens will be:

This tokenization does not provide enough information to reveal that this text is a line of code.
Nonetheless with a more atomic separation like this one:
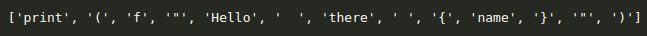
We feel that it captures more information about the syntax of the text.
Another enhancement is possible. As said before, we may not need the content of each word token. Even if some of them may disclose the syntax type (the word « print » is common in code texts), the computation burden to find them and the resulting complexity are not worthwhile. Rather, we may settle for the composition of the word. Accordingly, the above example becomes:

Having all this in mind, and according to our problematic, here are the token type that we should look for:
- for separation tokens:
- SPACE, NEWLINE and TAB are useful token type to appreciate the global structure of a text.
- DOT, SEMICOLON, COMMA, QUOTE, COLON, BRACKET, BRACE, PARENTHESIS, SLASH, BANG and QUESTION tokens may be specifically identified as they carry more information about the text articulation.
- PUNCTUATION for every other punctuation token.
- for word tokens:
- ALPHA, the token contains only alphabetic characters of any language (« print », »Hello », « Здравствуй », etc.).
- NUM, the token contains only numerical characters (« 0 », « 956543 », « 176156,987879 », etc).
- ALPHANUM, the token contains letters and numbers (‘ALPH4G0’, ‘w0w’, ‘BG465vU45uiTa7’, etc.).
- EMAIL, the token is an email address.
- URL, the token is a url address (‘www.website.com’, ‘https://website.is.awesome.uk’).
- IP, the token is an IP address.
- TAG, the token is an html tag (‘</a>’, ‘<div class= »my_class »>’, etc.).
As a result, a sentence could be separated as:


To implement this tokenizer, we took advantage of the ICU Library. This project tends to provide a standard support of the Unicode encodings. One of its feature is the rule break iterator that can tokenize Unicode phrases (handling specification of all the Unicode alphabets). It is the one used on many browsers when you double click on a word and it finds its border.
The power of ICU is its universal scope. It can handle tokenization of nearly every language that has an encoding in the Unicode system. In our implementation, we used a python wrapper of the ICU lib. We were able to customize the rules of the break iterator in order to add our own specific token types. Our program was so able to tokenize any texts according to all above specifications.
Yet this tokenizer was not enough to feed a machine learning model. We have only traded a string type data to a list of string. The next step is to use the tokenized notification to build numerical features. This is called preprocessing or feature extraction.
Preprocessing
All machine learning models must be fed with feature vectors. Those numerical arrays must represent the item to classify. In this part, we will explain how we selected the relevant features and how we computed them.
The first approach was to get the proportion of each token type for a given text.
Imagine we have only three token types: ALPHA, SPACE and PUNCTUATION. We can represent our text with a vector of three dimensions, each one referring to the term frequency of a token type.

This is a good start, but just counting token is not enough to guess the text syntax. For example, the text : ‘Hello world 🙂 !‘ will have the same representation as ‘: x! – y)‘ but the first belong to the NTL class and the second to the OTH class. We need a way to capture the information about tokens relative position to each other.
The idea we came across is to count sequences of token that are recurrent in a text. We can do this in two steps:
- get the set of recurrent sequences by browsing through the whole corpus and select the most recurrent ones
- count those sequences for each notification (in fact we keep the frequency as it is usually done in feature extraction to counteract unbalanced sizes)
A sequence is defined as a succession of more than one unique tokens or a sequence of two identical tokens, for example (ALPHA, SPACE), (APLHA, SPACE, DOT) or (DOT, DOT).
(ALPHA, SPACE, ALPHA) is invalid because ALPHA is present two times, (ALPHA) is also invalid as it is only one token long.
We found out two criteria to select sequences length. For both, we go through each tokenized notification of the corpus and process it this way:
- unlimited length
We take each token and start the longest series from it without finding an already seen token. We also select sequence of two identical tokens.

This allow for complexes sequences to be created.
The repartition of the top 10 sequences by label is the following :
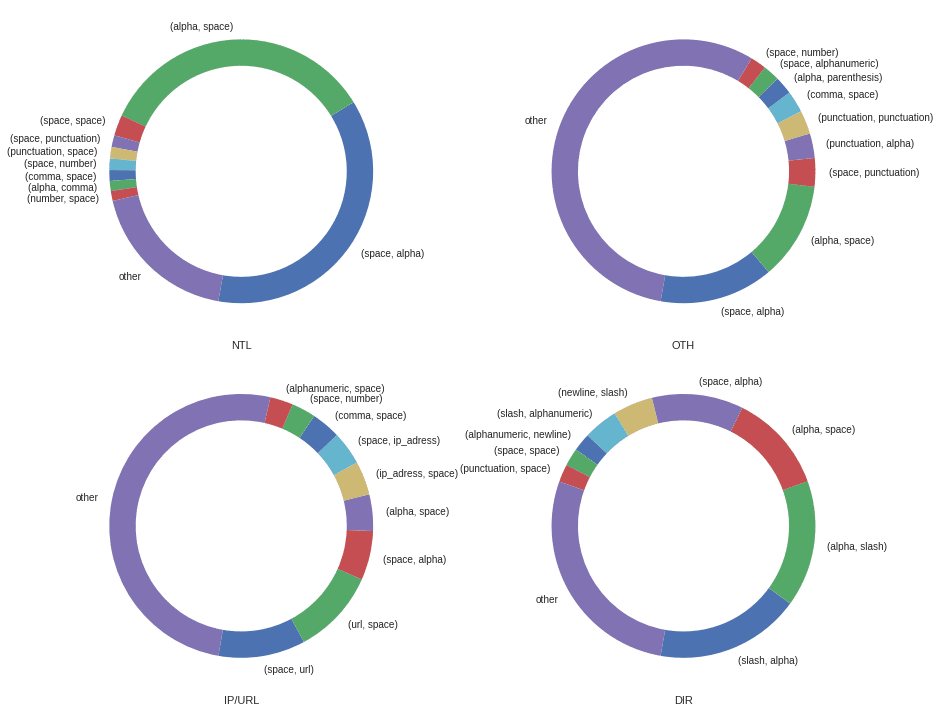
2 : unlimited length sequences repartition
2. limited length
We take each token and it neighbor to form two token sized sequences only.

This gives less sequences than the first method but they are also simpler.
The repartition of the top 10 sequences by label is the following:
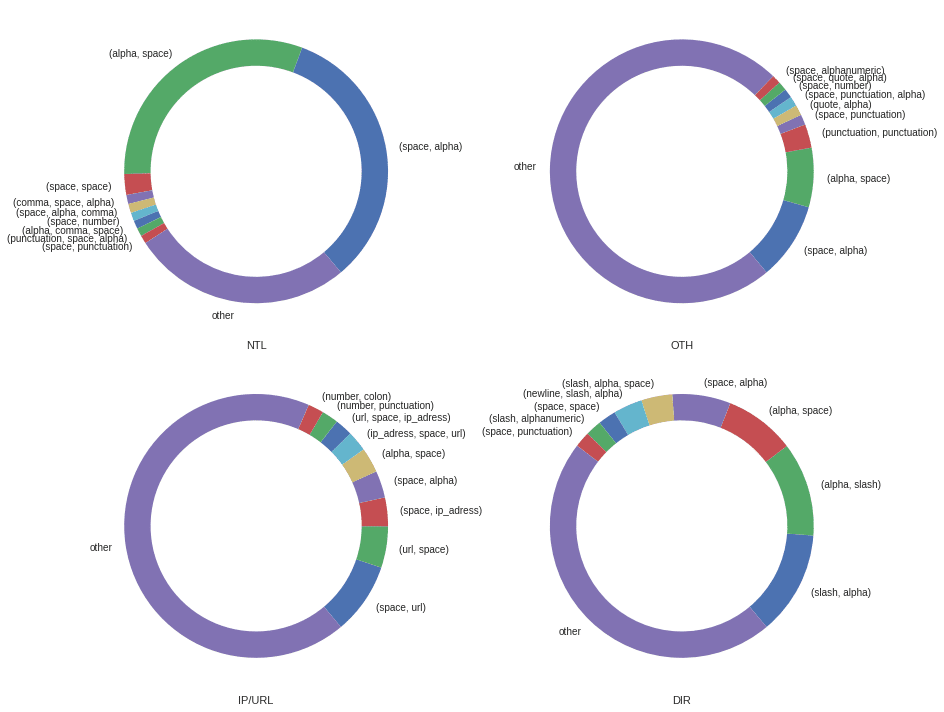
After computing the set sequences present in the notification corpus, we defined a minimum recurrence threshold to discard irrelevant sequences and thus reduce dimensionality of the resulting feature vector. We (arbitrarily) choose a minimum recurrence threshold of 10, this mean that we selected sequences that appeared at least 10 times.
With the first criteria, we found around 2000 unique sequences in the corpus, whereas the second gave us around 280 unique sequences. The first representations will create much more sparsed vectors (lots of 0) than the second representation.
Each sequence will be used as a feature to represent our notifications. The value of each feature (sequence) will be its occurrence rate (number of occurrence/ total number ) in the text. This allow us to have same size representations for every notifications.
For example, suppose we have built the following sequence set after going through a corpus using the second criteria.

As we have 7 sequences in our sequence set, the vector generated for a notification will have 7 dimensions, each associated to a sequence.

Here is the representation of the text « Hello world !! » :

As you can see in the figure, we have a total of 5 sequences in the text:
- (ALPHA,SPACE)
- (SPACE,ALPHA)
- (ALPHA,SPACE)
- (SPACE, PUNCTUATION)
- (PUNCTUATION,PUNCTUATION)
We can count 2 sequences of type (ALPHA, SPACE) so, in the index of this feature the value will be 2/5 = 0.4 .
Only one for (SPACE, ALPHA), (SPACE, PUNCTUATION) and (PUNCTUATION, PUNCTUATION) so the values will be 1/5 = 0.2.
There are no sequence of type (PUNCTUATION, SPACE) (PUNCTUATION, SPACE) (ALPHA,ALPHA) and (SPACE,SPACE). Their corresponding value will be 0.
We would use the same procedure for the other preprocess technique (with unlimited length).
To complete our vector we need to concatenate to it the occurrence rate of the tokens (here ALPHA, SPACE and PUNCTUATION)
For the text « Hello world !!« ,the result final vector will be :

We now have two different methods to represent our notifications into feature vectors (one with unlimited sequences and one with limited sequences).
The last part is now to implement a machine learning model and train it to predict the notification type. Their performances will decide what preprocessing technique to keep.
Models
Several models have been tested with both preprocessing techniques.
- SVM
- Random Forest
- K Neighbors
- Logistic Regression
- Multinomial Naive Bayes
- Dense Neural Network
We also tried a Neural Network with a Bidirectional LSTM cell using the tokenized notification as entry instead of the preprocessed notification, so that it could learn the optimal sequences itself.
We used the python libraries Scikit-Learn and Keras to implement those models.
Their optimal hyperparameters have been found empirically using grid search with cross validations for traditional machine learning models and the library Talos for the neural networks. Here some relevant ones
- SVM :
- sigmoid kernel for the unlimited preprocess
- rbf kernel for the limited preprocess
- K Neighbors : 5 neighbors
- Dense Neural Network : 2 hidden layers of 32 neurons each and a 4 neurons output layer
- LSTM : 1 LSTM cell with 64 units, a hidden layer of 32 neurons and a 4 neurons output layer.
Models were assessed through a benchmark comparing their performance to classify syntax type on a same corpus of notification. The selected metrics for evaluation were:
- Accuracy
This is a basic metric that gives good indications on how well a model is performing if the data is not highly unbalanced. As our data is unbalanced, using only this metric is not enough and it needs to be supported by another one.
- F1 macro
This is the second metric we used to evaluate our performance. In binary classification F1 score will give a harmonic mean of the precision (proportion of correct positive prediction) and the recall (proportion of positive correctly predicted). For our multiclass classification, we used the macro average of each class F1 score, which results in a bigger penalization than the weighted average when the model does not perform well with the minority classes.
Those metrics were measured on a test set to evaluate the models performance on never seen data, but also on the training set to evaluate overfitting.
Results
We used 75% of our test data set for training (~1500 notifications), 10% for validation (~200 notifications) and 15% for test (~300 notifications) to compare the model, with the two preprocessing criteria about the sequence length
- unlimited length :
| Model | Train accuracy | Test accuracy | Train F1_macro score | Test F1_macro score |
| SVM | 92% | 90% | 92% | 88% |
| Random Forest | 99% | 93% | 99% | 91% |
| K Neighbors | 99% | 85% | 99% | 79% |
| Logistic Regression | 94% | 90% | 94% | 88% |
| Multinomial Naive Bayes | 91% | 86% | 92% | 83% |
| Dense Neural Network | 94% | 91% | 88% |
- limited length :
| Model | Train accuracy | Test accuracy | Train F1_macro score | Test F1_macro score |
| SVM | 94% | 92% | 93% | 86% |
| Random Forest | 99% | 93% | 99% | 91% |
| K Neighbors | 99% | 94% | 99% | 90% |
| Logistic Regression | 91% | 89% | 89% | 86% |
| Multinomial Naive Bayes | 87% | 86% | 85% | 83% |
| Dense Neural Network | 93% | 93% | 91% |
For the LSTM, we the results are :
| Model | Train accuracy | Test accuracy | Train F1_macro score | Test F1_macro score |
| LSTM | 90% | 87% | 85% |
Nearly all models seem to have better performance than the LSTM which confirms that our feature representation is accurate.
The high dimensionality and the sparse property of the feature vectors generated by the unlimited preprocessing technique may probably explain why it has worst results globally.
One interpretation of those results is that the items classified in the OTH class may overlap on the others. A code document can contain pieces of Natural language (in code comment for example), or a configuration file can list ip addresses. This may « break » the linearity of the problem explaining why SVM, Logistic Regression and Bayesian models are less efficient than Random Forest and Dense Neural Network.
Here is a 2D representation of the data, using t-SNE algorithm for dimensional reduction :
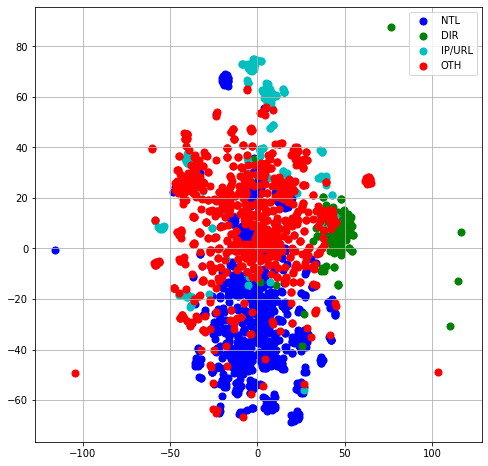
4 : t-SNE projection using unlimited length preprocessing
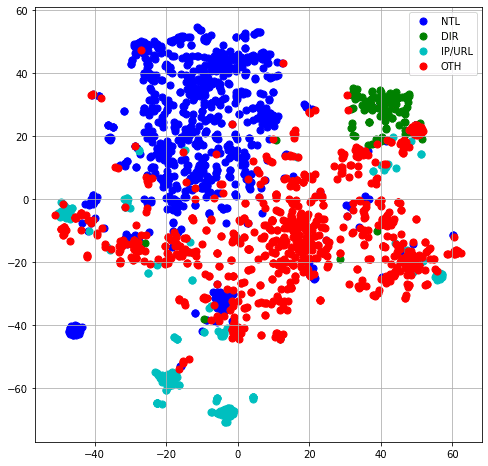
As we can see, the unlimited size representation is much more condensed than the limited size, so it is much harder to separate the different classes. In both representations, the OTH and the IP/URL classes are scattered.
As it is usually the case, Random Forest has good performance on non linear classification problem but its sensitiveness to data makes it prone to overfitting, which is what we may infer from the much higher train accuracy than the test accuracy.
The K Neighbors classifier has good scores with the limited preprocessing technique. However, this model seem also to overfit on the test data. Moreover, K Neighbors tend to have scaling issues as the data volume increases, becoming significantly slower at prediction time.
The best candidate for our syntax classification task seems to be the Dense Neural Network. This type of neural network is versatile and can model various problems (linear or not) and so are widely used.
Conclusion
This article relate our experimental researches on how to integrate artificial Intelligence to enhance the Cyber Threat Intelligence workflow. In particular, it describes how we designed and implemented a feature representation for a syntactic classification task by operating custom tokenization and sequences computation. To that end, several machine learning models were compared for the syntax classification. As result, it pointed out first and foremost that the feature extraction was relevant for this task. It also revealed that feeding those features to a fully connected Neural Network was the best option for this classification task, with an accuracy of 93%. All this work on syntax detection was a necessary preliminary step to identify natural language text in order to carry out semantic analysis at a later stage.
Authors
Achille Soulie
Habib Ghorbel







