Pour les analystes d’un SOC, il est d’une très grande importance de pouvoir connaître à quel moment une perte de journaux (logs) est en train de se produire ou a pu se produire. Lorsque les SIEM ne reçoivent plus les journaux de ses hôtes habituellement émetteurs, les règles de détection/corrélation ne peuvent correctement s’appliquer. Il est alors probable dans ce type de scénario, qu’il y ait une prise de connaissance tardive voir totalement absente par les analystes si un ou plusieurs incidents de sécurité ont pu se produire. Il en est de même si un attaquant a réussi à prendre le contrôle d’un hôte ou d’un compte utilisateur pour arrêter tous les processus de journalisation de telle sorte que son comportement illégitime passe inaperçu.
L’intelligence artificielle est perçue comme une avancée très profitable à notre société, permettant de prédire nos besoins et ainsi d’y répondre avec anticipation. Sa capacité à comprendre et analyser un contexte donné peut contribuer à détecter des anomalies ou des comportements inhabituels et ainsi, peut-il renforcer la détection pour le cas des pertes de journaux sur les hôtes ? C’est ce que nous allons découvrir dans cet article qui se décompose en cinq parties qui sont les suivantes :
- Les méthodes de calculs existantes
- Application du machine learning dans Splunk avec MLTK
- Les limites de la détection avec MLTK
- Une autre approche plus classique et cognitive
- Les avantages et les inconvénients
Les méthodes de calculs existantes
Considérant l’effet très négatif que peut engendrer les pertes de journaux sur la sécurité des systèmes d’une entreprise, il est essentiel de savoir comment les détecter. Pour cela, il existe trois méthodes qui peuvent être utilisées pour résoudre ce problème.
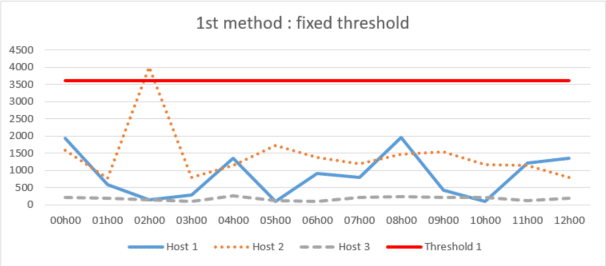
1 ère méthode : seuil fixe
Cette méthode consiste à estimer et définir un seuil de temps maximum fixe pour la non réception de journaux de manière globale ou pour chaque hôte. Dès lors qu’une entrée dépasse le seuil, l’alerte se déclenche.
Cette approche peut être efficace mais les seuils peuvent ne pas être justement adaptés à la variation de l’apparition des journaux des hôtes durant certaines périodes, et, par conséquent, une tolérance trop élevée peut être appliquée ou inversement. C’est une approche qui finit par nécessiter une analyse de la part des analystes ; elle n’est donc pas aussi efficace et fiable car elle peut déclencher un grand nombre de fausses alertes ou ignorer des pertes de journaux là où il ne devrait pas y en avoir.
2 ème méthode : écart type
La méthode de l’écart type qui consiste à calculer la variation de l’apparition des journaux autour de la moyenne historique pour définir des seuils automatisés plus précis. Elle peut être appliquée de manière globale ou pour chaque hôte.
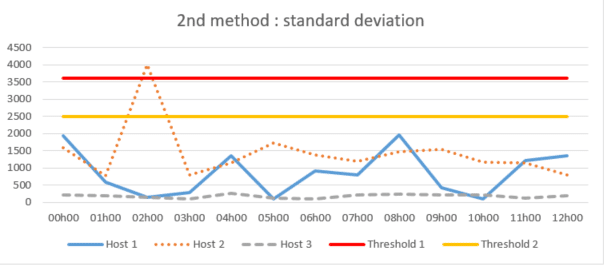
Bien que cela puisse sembler limiter les problèmes découlant de la première méthode exposée précédemment, une limitation effective peut se produire lorsqu’il y a une tendance ou une saisonnalité sur la disparition des journaux d’un hôte. La moyenne historique ne représentera pas avec précision la moyenne réelle pour une période donnée et, par conséquent, les seuils calculés risquent de ne pas détecter correctement une perte de journaux possible.
3 ème méthode : l’erreur de l’écart type
La méthode de l’erreur de l’écart type qui est similaire à la précédente mais qui vise quant à elle, à calculer l’erreur de prévision permettant d’obtenir une erreur moyenne. Elle permet ainsi de connaître plusieurs écarts types pour la définition de plusieurs seuils propres à plusieurs périodes pour chaque hôte.
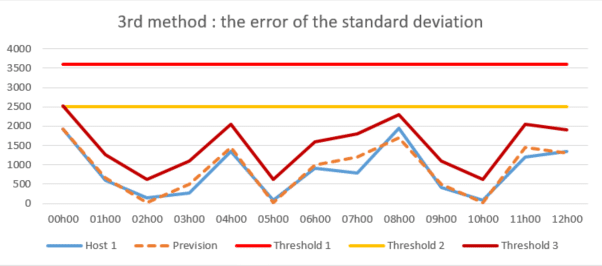
Cette méthode de détection plus intelligente analyse l’écart d’erreur de prévision au lieu de contrôler simplement l’apparition des journaux autour de la moyenne historique et permet ainsi de détecter les dépassements de seuil beaucoup plus précisément et de les ramener à une valeur plus plausible. Par conséquent, cette méthode est la plus adaptée pour répondre au problème de détection de pertes de journaux et peut être directement employée et adaptée grâce à l’application MLTK de Splunk.
Application du machine learning dans Splunk avec MLTK
Qu’est-ce que MLTK ?
Machine Learning Toolkit est une application gratuite qui s’installe sur la plateforme Splunk permettant d’étendre ses fonctionnalités et de fournir un environnement guidé de modélisation de machine learning avec :
- Une vitrine proposant une boîte à outils d’apprentissage automatique. Celle-ci contient des exemples prêts à l’emploi avec des ensembles de données réels pour comprendre rapidement et facilement le fonctionnement des méthodes et des algorithmes mis à disposition.
- Un assistant d’expérimentation pour concevoir de manière guidée ses propres modèles et les tester.
- Un onglet de recherche SPL intégrant les commandes propres à MLTK permettant aussi de tester et d’adapter ses propres modèles.
- 43 algorithmes disponibles et utilisables directement depuis l’application et également une librairie python contenant plusieurs centaines d’algorithmes open source pour le calcul numérique en libre accès.
MLTK permet donc de répondre à différents objectifs tels que :
- Prédire des champs numériques (régression linéaire)
- Prédire les champs catégoriels (régression logistique)
- Détecter les valeurs numériques aberrantes (statistiques de distribution)
- Détecter les valeurs aberrantes catégorielles (mesures probabilistes)
- Prévision de séries temporelles
- Regrouper les événements numériques
Parmi les objectifs cités ci-dessus auxquels MLTK peut satisfaire, un seul modèle de machine learning peut répondre à la détection de la perte de journaux avec la méthode de l’erreur de l’écart type : la détection des valeurs aberrantes.
La détection des valeurs aberrantes pour les hôtes manquants
La détection des valeurs aberrantes est l’identification de données déviantes par rapport à un ensemble de données. Pour obtenir les données dans ce cas d’usage, il suffit de relever l’écart de temps qu’il a y entre chaque log émis par l’hôte et de nettoyer les valeurs nulles qui peuvent fausser les résultats. Ensuite, en ce qu’il s’agit de l’application du modèle, on calcule l’erreur de l’écart type pour chacune des données pour détecter les valeurs aberrantes.
Voici un exemple de modèle de prévision dans MLTK sur la perte de journaux pour un seul hôte. Les valeurs aberrantes (points jaunes) sont les points de données qui se situent en dehors de l’enveloppe d’aberration (zone bleue claire). La valeur qui se trouve à droite du graphique (14) indique le nombre total de valeurs aberrantes :
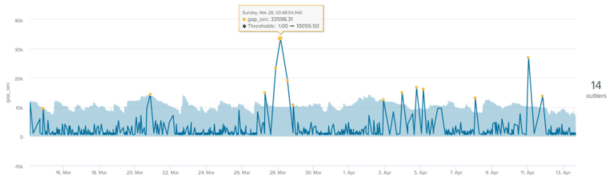
On remarque que l’enveloppe d’aberration ou les seuils calculés suivent plutôt bien l’allure générale de la courbe mais qu’un certain nombre de valeurs aberrantes sont tout de même remontées.
Les limites de la détection avec MLTK
Même si cette méthode permet de prendre en compte la saisonnalité de la perte des journaux, elle demande tout de même une certaine régularité. Certains hôtes peuvent émettre de manière très irrégulière durant n’importe quelle période et ainsi créer de fausses valeurs aberrantes dans les ensembles de données.
Par exemple, c’est le cas pour cet hôte qui sur une période de 2 à 30 jours, va conserver un coefficient de variation élevé. Ce coefficient correspond à la mesure relative de la dispersion des données autour de la moyenne : Il est égal au ratio de l’écart-type par rapport à la moyenne. Plus la valeur du coefficient de variation est élevée, plus la dispersion autour de la moyenne est grande. Or, ci-dessous, les coefficients de variation sont supérieurs à 1,5, c’est-à-dire que l’écart type représente plus de 1,5 fois la moyenne. On considère qu’un écart-type commence à être élevé lorsqu’il représente la moitié de la moyenne, il est donc relativement élevé dans cet exemple :
| Périodes | 2_jours | 7_jours | 14_jours | 21_jours | 30_jours |
| Fréquence totale | 144 | 404 | 902 | 1338 | 1921 |
| Population totale | 258591 | 688776 | 1295373 | 1900168 | 2653629 |
| Médiane | 600 | 600 | 600 | 600 | 600 |
| Moyenne | 1795.77 | 1708.09 | 1436.11 | 1420.16 | 1381.38 |
| Valeur minimale | 598 | 580 | 559 | 559 | 559 |
| Valeur maximale | 28799 | 28799 | 31199 | 37204 | 37204 |
| Ecart type | 3301 | 2869 | 2416 | 2446 | 2304 |
| Coefficient de variation | 1.84 | 1.68 | 1.68 | 1.72 | 1.67 |
Il en est de même si on se focalise sur des jours précis de la semaine sur une période de 30 jours :
| Périodes | Lundi | Mardi | Mercredi | Jeudi | Vendredi | Samedi | Dimanche |
| Fréquence totale | 403 | 403 | 356 | 328 | 268 | 90 | 73 |
| Population totale | 431224 | 407397 | 344989 | 346248 | 390887 | 383993 | 386387 |
| Médiane | 600 | 600 | 600 | 600 | 601 | 2104.5 | 3000 |
| Moyenne | 1070.03 | 1010.91 | 969.07 | 1055.63 | 1318.62 | 4266.59 | 5292.97 |
| Valeur minimale | 595 | 559 | 580 | 592 | 594 | 590 | 598 |
| Valeur maximale | 7200 | 7200 | 8400 | 10800 | 8399 | 37204 | 31199 |
| Ecart type | 988 | 835 | 794 | 1056 | 1379 | 5771 | 6871 |
| Coefficient de variation | 0.92 | 0.83 | 0.82 | 1.00 | 1.05 | 1.35 | 1.30 |
De plus, pour les entrées qui sont très verbeuses, une demande de performance côté SIEM est aussi importante lors des différents calculs à cause d’un trop grand nombre de journaux. Il est alors nécessaire de réduire la période d’apprentissage du modèle impactant ainsi la fiabilité des seuils calculés, car, plus une période d’apprentissage est longue, plus elle permet d’emmagasiner des données et donc de prédire de meilleurs seuils.
Enfin, il est très difficile à l’aide de cette solution de pouvoir appliquer ce modèle sur un ensemble d’hôtes. Chaque entrée émet des journaux à sa manière et il est donc obligatoire d’ajuster les calculs pour chaque entrée pour que ce modèle fonctionne correctement. Ce travail d’adaptation au cas par cas peut représenter une charge de travail considérable si plusieurs centaines voire milliers d’hôtes doivent être surveillés.
Une autre approche plus classique et cognitive
Observant que la solution cognitive peut détecter les dépassements de seuil beaucoup plus précisément et à des valeurs plus plausibles, elle n’en est pas moins contraignante. En effet, celle-ci demande une certaine régularité dans les données, une période d’apprentissage assez longue et donc une puissance de calcul importante et d’affiner les calculs au cas par cas.
Pour pallier ces différents contraintes, une autre approche plus classique et reposant sur l’idée d’une solution cognitive a été pensé puis conçue pour une application générale sur un ensemble d’hôtes.
Elle consiste en premier lieu à reposer sur le comptage d’évènements plutôt qu’au calcul de l’écart de temps entre chaque évènement. Ce changement de paramètre est très important car même si le type de donnée n’est plus le même, la puissance de calcul demandée est beaucoup moins importante et autorise ainsi d’avoir une période d’apprentissage plus longue.
Ce modèle effectue ensuite des statistiques pour appliquer un seuil pour chaque hôte en fonction de leur niveau de verbosité sur plusieurs tranches horaires. Des coefficients sont par la suite appliqués à ces seuils en fonction de la variation des valeurs qui ont pu être mesurées dans le passé dans le but d’affiner et d’obtenir un seuil précis pour chaque hôte à un horaire précis. Même si cette façon de calculer les seuils peut être considérée comme plus arbitraire, elle n’en est pas moins précise que la méthode reposant sur le machine learning. Elle permet en outre, de garder la main sur la tolérance des pertes de journaux et d’affiner les seuils au cas par cas sur un ensemble d’hôtes.
Les avantages et les inconvénients
Tous les systèmes courants génèrent des journaux d’évènements, dont la volumétrie varie dans le temps (notamment selon leur activité) ce qui crée de fait une certaine variabilité. Par conséquent, il n’existe pas de méthode totalement fiable pour détecter la perte de journaux. Quelle que soit la nature de cette variance, bon nombre de facteurs extérieurs peuvent se produire et donc nuire gravement à la fiabilité de la méthode employée. Les pertes de journaux résultent souvent d’évènements extérieurs, tel qu’un dysfonctionnement de l’agent de collecte ou de l’API de transmission, des décommissionnements de machines ou des redémarrages qui peuvent être dus à des contraintes d’infrastructures, systèmes ou logicielles rendant temporairement impossible la collecte des journaux.
Même si le machine learning fait beaucoup parler de lui en ce moment et qu’il aurait pu être un bon axe d’amélioration pour répondre à cette problématique. La façon dont il est présenté laisse souvent supposer qu’il est capable de répondre à n’importe quel problème tant qu’un contexte a bien été défini et qu’il y la présence de données. Or, ce n’est évidemment pas le cas. Bien que le machine learning permette d’augmenter les taux de détection, de détecter au plus tôt les attaques et d’améliorer la capacité d’adaptation aux évolutions, les machines sont constamment en cours d’apprentissage.
Dans la plupart des cas, l’apprentissage automatique est une habile combinaison entre technologie et intervention humaine. C’est pourquoi, l’approche la plus classique répond mieux au contexte de ce cas d’usage. En effet, que ce soit avec MLTK ou une autre solution d’apprentissage automatique, il est difficile de prédire les données et d’obtenir des seuils de confiance acceptable pour chaque hôte à cause de la grande variabilité qui subsiste entre eux.







