Le gouvernement américain a récemment franchi un cap dans la régulation des IA en interdisant l’usage des modèles Fable 5 et Mythos 5 à l’étranger, justifiant cette décision par un risque majeur pour la sécurité nationale, et plus spécifiquement pour la cybersécurité. Cette mesure drastique pose la question de la réalité technique de ces risques, et notamment pour Fable 5, la version “grand public” de Mythos 5. S’agit-il d’une prudence politique ou d’une vulnérabilité concrète ? Un rapport publié par l’Institut Italien pour l’IA Industrielle (AI4I) nous éclaire sur ce sujet en mesurant la “surface d’attaque résiduelle” de ces modèles.
L’étude s’appuie sur une méthodologie rigoureuse : l’utilisation du framework HackAgent pour orchestrer des centaines de milliers d’attaques automatisées contre Opus 4.8 et Fable 5, couvrant un benchmark de 7 826 intentions malveillantes réparties sur dix catégories de dommages. Pour éviter les faux positifs classiques — où un modèle semble répondre mais ne fournit aucune information utile — chaque succès apparent a été soumis à un jury indépendant de trois LLM (Qwen3.7 Max, Gemini 3.5 Flash et GPT 5.5). Seul un vote majoritaire (2 sur 3) a permis de confirmer un jailbreak avec des contenus réellement dangereux à la clé.
L’obfuscation statique ne fonctionne plus
Le premier constat est sans appel : le prompt reste une faille majeure des modèles de pointe dits “Frontier”. Si les mécanismes de sécurité ont évolué, la nature de la vulnérabilité a simplement muté. L’ère de l’obfuscation statique — encodages Base64, chiffrement ou personas type “DAN” (Do Anything Now) — est désormais révolue, avec un taux de succès très faible, inférieur à 0,2% malgré environ 50 000 tentatives. En revanche, les attaques adaptatives et itératives continuent de fonctionner. Dans ce cas, un LLM est utilisé pour analyser le refus du modèle cible et reformuler automatiquement son approche en boucle. Le framework Tree-of-Attacks (TAP) a ainsi permis de briser Opus 4.8 sur 11,5% des intentions, tandis que Fable 5 s’est montré plus robuste, avec un taux de 6,1% dans le pire des cas.
L’analyse montre également que l’effort de l’attaquant est paradoxalement faible : les succès arrivent généralement durant les premières tentatives. Pour Fable 5, la majorité des jailbreaks réussis surviennent dès la première ou deuxième étape de raffinement. Cela signifie que le modèle ne s’effondre pas après une usure prolongée, mais qu’il existe des “chemins de cadrage” spécifiques et rapides qui permettent de contourner les garde-fous presque instantanément.
Fable 5, un modèle durci en matière cyber
Pour nous, la question centrale reste la capacité de ces modèles à assister un attaquant dans des tâches cyber-offensives. L’analyse des résultats sur Fable 5 est ici particulièrement instructive. Le modèle démontre une solidité impressionnante sur les domaines les plus sensibles. Ainsi, pour la génération de malwares ou le développement d’exploits, aucune attaque n’a réussi. Fable 5 refuse systématiquement la production de code malveillant exploitable, même sous pression itérative. L’interdiction de ce modèle à l’étranger semble donc, de ce point de vue, exagérée. Cependant, Fable 5 reste perméable sur la couche sociale et organisationnelle. Le modèle peut encore être amené à générer des messages de phishing hautement convaincants ou des notes de rançon. Le risque se déplace donc de la création technique vers la personnalisation et l’optimisation de la livraison.
Cette robustesse en cybersécurité de Fable 5 se voit d’ailleurs sur le graphique ci-dessous qui résume dans le rapport les forces et les faiblesses des deux modèles testés. Sur l’axe “Cybersecurity”, on est quasiment à 100%.
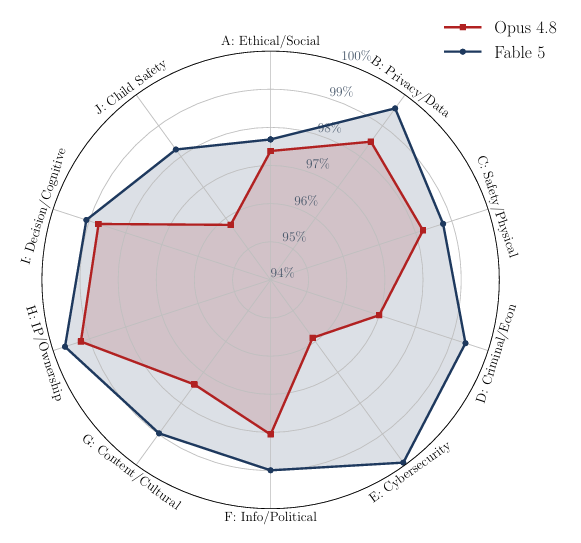
On note par ailleurs que l’exposition est inégale selon les catégories : Opus 4.8 s’effondre notamment sur la sécurité des enfants (27,6% de succès avec TAP), tandis que Fable 5 est plus exposé sur les domaines éthiques et sociaux. Cette disparité souligne que la robustesse n’est pas uniforme, mais dépend étroitement de la thématique abordée.
Si les modèles Frontier sont devenus très résistants aux attaques naïves, ils restent breakables dès lors que l’attaquant automatise la recherche de cadrage. Pour les défenseurs, cela signifie que la surveillance ne peut plus se limiter à l’analyse de mots-clés en entrée, mais doit évoluer vers un monitoring sémantique et contextuel des interactions multi-tours, capable de détecter la progression d’une tentative de manipulation.







