The US government recently took a step forward in regulating AI by prohibiting the use of models Fable 5 and Mythos 5 abroad, justifying this decision by citing a major risk to national security, and more specifically to cybersecurity. This drastic measure raises the question of the technical reality of these risks, particularly for Fable 5, the "consumer" version of Mythos 5. Is this a matter of political prudence or a real vulnerability? report published by the Italian Institute for Industrial AI (AI4I) sheds light on this subject by measuring the "residual attack surface" of these models.
The study is based on a rigorous methodology: the use of the framework HackAgent to orchestrate hundreds of thousands of automated attacks against Opus 4.8 and Fable 5, covering a benchmark of 7,826 malicious intentions divided into ten damage categories. To avoid classic false positives—where a model appears to respond but provides no useful information—each apparent success was subjected to a independent jury of three LLMs (Qwen3.7 Max, Gemini 3.5 Flash and GPT 5.5). Only a majority vote (2 out of 3) was enough to confirm a jailbreak with genuinely dangerous content included.
Static obfuscation no longer works
The first observation is undeniable: The prompt remains a major flaw cutting-edge models known as "Frontier" models. While security mechanisms have evolved, the nature of the vulnerability has simply mutated. The era of static obfuscation—Base64 encodings, encryption, or "DAN" (Do Anything Now) type personas—is now over, with a very low success rate., less than 0.2% despite approximately 50,000 attempts. However, the adaptive and iterative attacks continue to function. In this case, an LLM is used to analyze the rejection of the target model and automatically reformulate its approach in a loop. The framework Tree-of-Attacks (TAP) thus made it possible to break Opus 4.8 on 11.5% of intentions, while Fable 5 proved more robust, with a rate of 6,1% in the worst-case scenario.
The analysis also shows that the attacker's effort is paradoxically low: successes usually occur during the first attempts. For Fable 5, the majority of successful jailbreaks occur during the first or second refinement stage. This means that the model doesn't break down after prolonged wear and tear, but rather that there are specific and rapid "frame paths" that allow bypassing the safeguards almost instantly.
Fable 5, a cyber-hardened model
For us, the central question remains the ability of these models to assist an attacker in cyber-offensive tasks. The analysis of the results on Fable 5 is particularly instructive here. The model demonstrates impressive robustness in the most sensitive areas. Thus, for malware generation or exploit development, No attacks were successful. Fable 5 systematically rejects the production of exploitable malicious code, even under iterative pressure. From this perspective, banning this model abroad therefore seems excessive. However, Fable 5 remains vulnerable at the social and organizational level. The model can still be used to generate highly convincing phishing messages or ransom notes. The risk thus shifts from technical creation to the customization and delivery optimization.
Fable 5's robust cybersecurity is further demonstrated in the graph below, which summarizes the strengths and weaknesses of the two tested models in the report. On the "Cybersecurity" axis, the score is almost 100%.
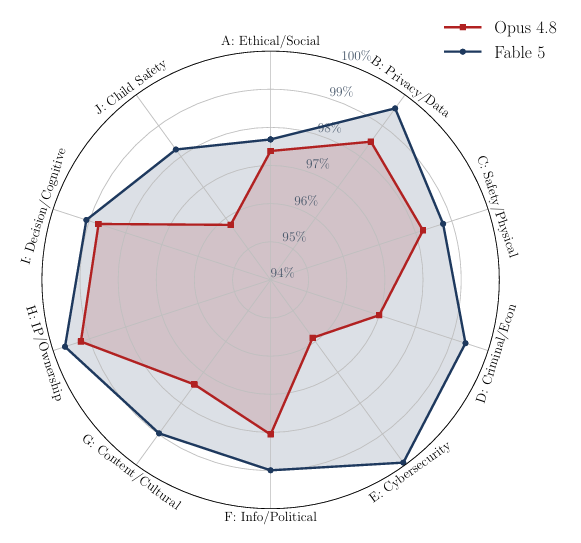
It should also be noted that the exposure is uneven across categories: Opus 4.8, in particular, collapses in the Child safety (27.6% success rate with TAP), Fable 5, on the other hand, focuses more on ethical and social issues. This disparity highlights that robustness is not uniform, but depends heavily on the subject matter.
While Frontier models have become highly resistant to naive attacks, they remain breakable as soon as the attacker automates the framing search. For defenders, this means that monitoring can no longer be limited to analyzing input keywords, but must evolve towards a semantic and contextual monitoring multi-turn interactions, capable of detecting the progress of a manipulation attempt.







